Think About Load, Scale, and Capacity Planning
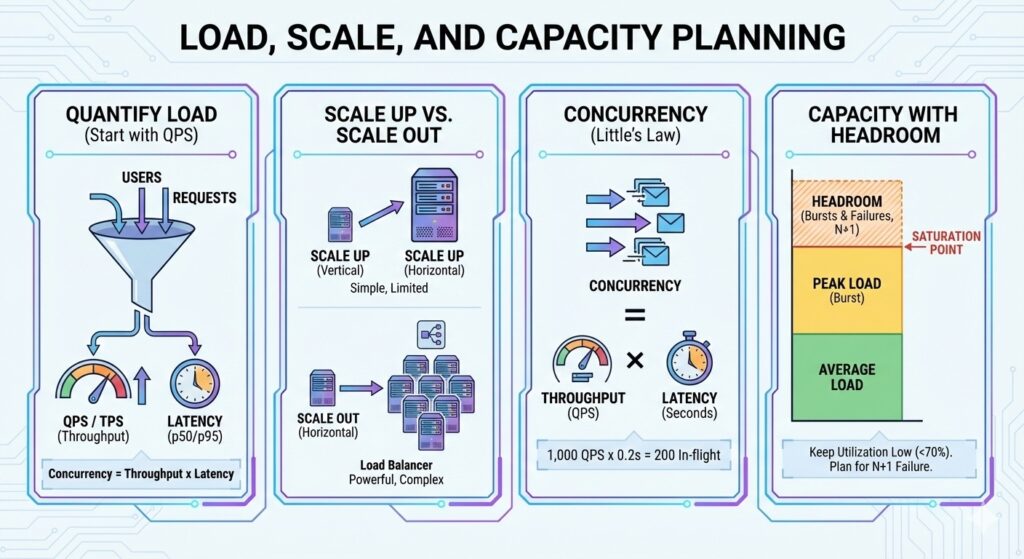
TL;DR / Key Takeaways The Three Numbers You Always Need A simple rule: If you do 1,000 QPS and average latency is 200 ms (0.2 s), concurrency is about 200 requests in flight. Worked Example: Concurrency to Instance Count Assume a peak of 2,500 QPS and p95 latency of 120 ms. Utilization and Queueing Intuition […]
Think About Load, Scale, and Capacity Planning Read More »